
O doutor Duque Fernández analizou a evolución de sistemas de tradución automática que buscan traducir un idioma orixe a outro idioma obxectivo
O relator participou no seminario de IA que organiza a UNED en Ourense e explicou que a tradución automática aínda non está resolta pois mostra "problemas coas palabras polisémicas, expresións propias dun idioma, rumbos variados, xa sexan de xénero, de raza ou outros".

OURENSE, 9 de abril de 2021.- O profesor axudante e doutor Andrés Duque Fernández, do departamento de Linguaxes e Sistemas Informáticos da ETSII da UNED, expuxo esta mañá a conferencia Tradución automática: evolución histórica, aproximacións actuais e desafíos abertos. Fíxoo desde o Centro de Intelixencia Artificial de Ourense. O doutor Duque explicou a evolución deste tipo de tradución, remontándose aos anos 50 do pasado século. Así, dixo que a principios daquela década xurdiu a tradución automática motivada pola Guerra Fría e consistía en primeiras traducións do ruso ao inglés. Naquela época utilizábanse sistemas baseados en regras (Rule Based Machine Translation, RBMT) consistentes en dicionarios bilingües e conxuntos de regras lingüísticas para cada idioma.
En 1954 produciuse o experimento Georgetown-IBM para a tradución do ruso ao inglés nos dominios de: química orgánica, política social, dereito, matemáticas, metalurgia… Incluía seis regulas básicas e 250 palabras no vocabulario. Tales regras eran:
- Regra 1: Reordenación de palabras
- Regra 2: Selección de seguinte
- Regra 3: Selección e reordenación
- Regra 4: Selección de anterior
- Regra 5: Selección por omisión
- Regra 6: Subdivisión ou selección de inserción
Nos anos 80 do século XX xurdiron os sistemas baseados en exemplos (EBMT) que supuxeron un paso previo á tradución automática estatística e neuronal. Baséase en ideas como a explicada por Nagao sobre a tradución humana: “a tradución dunha frase non se consegue facendo unha análise lingüístico profundo. No seu lugar, normalmente o que facemos é descompoñela en elementos máis pequenos e traducilos ao idioma obxectivo. Por último, recompoñemos estes fragmentos para formar a frase final”.
Estes sistemas conlevan tres procesos principais: emparellamento, aliñamento e recombinación. As técnicas de emparellamento pódense basear en caracteres, palabras e patróns. No emparellamento baseado en caracteres pódese utilizar a distancia de edición e é sinxelo de implementar, pero non ten en conta a semántica, é dicir, que non se extraen emparellamentos de sinónimos, por exemplo.
A técnica baseada en palabras mostra o uso de tesauros e dicionarios para atopar palabras con significados similares; necesita un maior procesamento lingüístico e maior base de coñecemento.
Por último, a técnica baseada en patróns supón a xeneralización a través de clases equivalentes; utilízanse tamén patróns sintácticos e require o uso de analizadores sintácticos ou parsers para ambos os idiomas.
O doutor Duque Fernández falou igualmente da tradución automática EBMT pura, ou en tempo de execución, que ten o seu propio algoritmo, é un modelo sinxelo, especialmente útil para palabras descoñecidas ou termos moi especializados; non resulta de tanta utilidade como modelo de tradución completo; pódese usar como complemento a outros modelos de tradución e é computacionalmente lento.
Os sistemas da EBMT baseada en exemplos compilada comprenden aprendizaxe de persoais de tradución a partir dos exemplos, redúcese o problema de dispersión de datos mediante a xeneralización e auméntase a cobertura.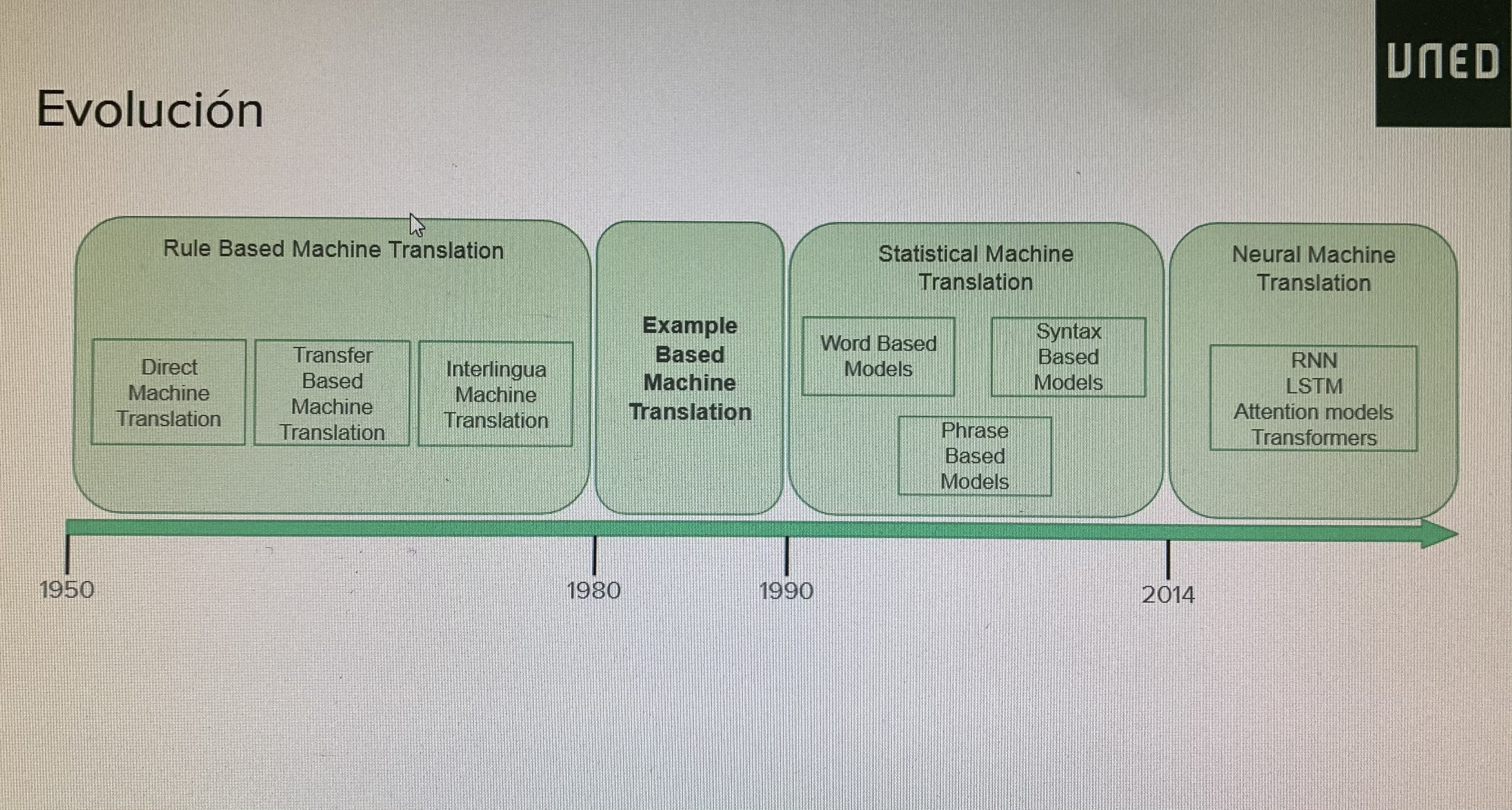
Segundo o relator, os conflitos principais da EBMT son: adecuación do corpus de exemplos (exemplos que se reforzan uns a outros, exemplos con conflitos e exemplos contraditorios); selección do tipo de emparellamento; en xeral EBMT funciona ben con datos específicos en dominios concretos, pero en xeral non se utiliza con fins comerciais. Este sistema rapidamente viuse eclipsado pola tradución automática estatística, aínda que segue presente en modelos híbridos.
Falou igualmente dos corpus paralelos como recurso fundamental para a tradución automática empírica, dirixida por datos. Son coleccións de textos en dous ou máis idiomas, presentan aliñamento a nivel de palabra, frase ou sentenza, son diferentes aos corpus comparables, nos que os fragmentos de texto son similares e proceden do mesmo dominio (xénero, temas tratados, etc). Con todo, di Andrés Duque, estes corpus comparables non teñen por que estar aliñados. Os corpus comparables son pares de corpus monolingües que se colleitaron usando as mesmas técnicas de mostraxe.
Dos corpus paralelos espérase limpeza, apropiación ao dominio/xénero/estilo e un tamaño suficientemente grande. Estes corpus teñen xeración manual (profesional ou a través de crowdsourcing, segundo a estimación de compromiso custo/beneficio); e xeración masiva, con procedemento sinxelo e capaz de recompilar grandes cantidades de datos; para xerar corpus de forma masiva é necesaria a detección, tanto automática ou non, de dominios web con datos paralelos. Os problemas que presenta esta xeración masiva son datos ruidosos, datos xa xerados por tradución automática e dominios particulares.
O relator mencionou tres corpus:
- Europarl, con 21 idiomas, 1,4 millóns de frases e 31 millóns de palabras
- JRC- Acquis, con 22 idiomas; 2,9 millóns de frases de media e unha media de 48 millóns de palabras
- OpenSubtitles, con 62 idiomas, unha media de 54 millóns de frases e 358 millóns de palabras de media.
Seguindo co avance temporal da tradución automática, o profesor sinalou como ao iniciarse a década dos anos 90 do século pasado xurdiu a tradución estatística ( SMT) como modelo probabilístico a partir dos datos de corpus paralelos. Explicou a súa base teórica e o seu modelo de tradución así como a súa decodificación. Como sinala Duque, denomínase decodificador ao módulo de tradución automática que se encarga de realizar a tradución propiamente dita, a partir do modelo aprendido. E sinalou diversos enfoques:
- Algoritmos voraces: é unha tradución literal refinada iterativamente mediante heurísticas
- Beam search: trátase dunha decodificación de esquerda a dereita na que o espazo de procura é exponencial á lonxitude da frase e prodúcese a redución do devandito espazo a partir do uso de heurísticas para reducir as hipóteses. Esta decodificación non garante unha solución óptima, pero é unha opción altamente eficiente.
A SMT baseada en frases ofrece segmentación en frases, non se entende frase como elemento lingüístico, senón como unha secuencia de palabras consistente co aliñamento a nivel de palabra. Unha frase pode estar formada por un n-grama de palabras como elemento atómico. A segmentación en frases leva á tradución e á reordenación. Hai diversas técnicas para a aliñación a nivel de frase: xeración a partir do aliñamento a nivel de palabra, persoais de aliñamento e modelos conxuntos. A tradución automática estatística baseada en frases (Phrase-based SMT) supuxo a estado da arte na industria ata aproximadamente o ano 2016.
Este sistema baseado en frases ten a vantaxe de permitir a tradución moitos a moitos, usa o contexto local para a tradución e as súas limitacións son frases non continuas, algunhas transformacións sintácticas e o aliñamento, que segue ofrecendo diversos problemas.
A tradución automática estatística (SMT) baseada en sintaxe resulta máis útil cando se tratan idiomas con estruturas moi diferentes. Incorpórase información sintáctica ao proceso de tradución utilizando árbores e formalismos gramaticais.
En xeral, os problemas que rexistra a SMT son o aliñamento a nivel de palabra, de frase; anomalías estatísticas como o traducir erroneamente nomes propios; aplicación de conxuntos de adestramento xenéricos a dominios específicos; frases feitas, expresións e outros problema dáse na orde das palabras. Os desafíos pasan por crear corpus, conseguir xestionar os resultados inesperados e pares de idiomas con estruturas moi diferentes. Como sinala o relator, a SMT é un campo de investigación enorme cuxos mellores sistemas en xeral son complexos (centos de detalles importantes, subcomponentes deseñados a man; enxeñería de características para capturar fenómenos específicos dun idioma; recursos extra como táboas de equivalencia, etc. E esforzo humano para cada par de idiomas.
Outro sistema son as redes neuronais e a aprendizaxe profunda. A tradución automática neuronal (NMT) utiliza unha única rede neuronal, supuxo unha revolución no ano 2014 aproximadamente. Estableceuse como estado da arte na industria desde 2016 e presenta unha arquitectura secuencia a secuencia. Duque sinala que a NMT pasou de ser unha actividade de investigación marxinal ao método estándar en dous anos.
No 2014 publicouse o primeiro paper respecto diso. En 2016 Google Translate pasou a utilizar a NMT. O SMT desenvolvido por centos de persoas durante anos foi desbancado por sistemas NMT adestrados por unhas poucas persoas en meses. Por último, en canto a vantaxes, o NMT presenta mellores resultados, mellor uso do contexto; mellor similitude entre frases, maior fluidez, sen subcomponentes e supón menor esforzo humano. Como inconvenientes presenta a interpretabilidad dos resultados, (con sistemas de caixa negra, certas melloras respecto a a atención e dificultades na depuración) e é difícil de controlar, e por iso, hibridar.
En canto a se está resolta a tradución automática, Andrés Duque presenta varios exemplos para demostrar que non é así: problemas coas palabras polisémicas, expresións propias dun idioma, rumbos variados, xa sexan de xénero, de raza ou outros. Os principais desafíos pasan pola xestión das palabras fose do vocabulario (copiado de palabras, tradución baseada en caracteres e técnicas de subwording); corpus paralelos, sobre todo en idiomas con poucos recursos: para eles, trabállase na transferencia de aprendizaxe de modelos pre-adestrados e en medidas de axuste, así como na tradución automática non supervisada. Outro desafío é o mantemento do contexto en textos longos (con investigacións sobre tradución guiada polo contexto, modelado separado do contexto para a súa utilización posterior e reforzo do discurso). Ou o rumbo en datos de adestramento (para reducilo utilízanse corpus con anotacións concretas, por exemplo de xénero; tamén se persegue a eliminación do rumbo anterior ao adestramento ata conseguir datos non nesgados, e ou a eliminación do rumbo posterior ao adestramento utilizando medidas de axuste.
Este seminario de IA da UNED en Ourense está patrocinado polo Vicerreitorado de Investigación, Transferencia do Coñecemento e Divulgación Científica da UNED.
Ver a conferencia de Andrés Duque aquí.
 UNED Ourense
UNED Ourense
Comunicación




