
El doctor Duque Fernández desmenuzó la evolución de sistemas de traducción automática que buscan traducir un idioma origen a otro idioma objetivo
El ponente participó en el seminario de IA que organiza la UNED en Ourense y explicó que la traducción automática aún no está resuelta pues muestra "problemas con las palabras polisémicas, expresiones propias de un idioma, sesgos variados, ya sean de género, de raza u otros".

OURENSE, 9 de abril de 2021.- El profesor ayudante y doctor Andrés Duque Fernández, del departamento de Lenguajes y Sistemas Informáticos de la ETSII de la UNED, expuso esta mañana la conferencia La traducción automática: evolución histórica, aproximaciones actuales y desafíos abiertos. Lo hizo desde el Centro de Intelixencia Artificial de Ourense. El doctor Duque explicó la evolución de este tipo de traducción, remontándose a los años 50 del pasado siglo. Así, dijo que a principios de aquella década surgió la traducción automática motivada por la Guerra Fría y consistía en primeras traducciones del ruso al inglés. En aquella época se utilizaban sistemas basados en reglas (Rule Based Machine Translation, RBMT) consistentes en diccionarios bilingües y conjuntos de reglas lingüísticas para cada idioma.
En 1954 se produjo el experimento Georgetown-IBM para la traducción del ruso al inglés en los dominios de: química orgánica, política social, derecho, matemáticas, metalurgia… Incluía seis reglas básicas y 250 palabras en el vocabulario. Tales reglas eran:
- Regla 1: Reordenación de palabra
- Regla 2: Selección de siguiente
- Regla 3: Selección y reordenación
- Regla 4: Selección de anterior
- Regla 5: Selección por omisión
- Regla 6: Subdivisión o selección de inserción
El ponente mencionó la traducción RBMT basada en transferencia, cuyo esquema es: análisis, transferencia y generación. Se parte del análisis gramatical inicial para efectuar la traducción de estructuras en lugar de palabras simples, desarrollando reglas gramaticales. Ofrece una mayor complicación por el elevado número de combinaciones posibles y presenta necesidad de reglas específicas para cada paso del proceso.
La traducción RBMT también puede ser interligüe, con representación intermedia independiente del lenguaje. Esta representación es muy valiosa para sistemas multilingües y, como dice Duque, es “el Santo Grial de los lingüistas, incluso en la actualidad. Gracias a toda la investigación en esta línea tenemos representaciones del lenguaje a múltiples niveles (morfológico, sintáctico, semántico…)”.
En cuanto a las ventajas de la RBMT, destacan tres: calidad consistente y predecible; reproducibilidad de los resultados y posibilidad de adaptación a dominios correctos. Tiene, además, inconvenientes destacando la pobreza morfológica (variabilidad de palabras); falta de fluidez (traducciones muy artificiales); alto coste de desarrollo y adaptación además de un mal manejo de excepciones a las reglas.
En los años 80 del siglo XX surgieron los sistemas basados en ejemplos (EBMT) que supusieron un paso previo a la traducción automática estadística y neuronal. Se basa en ideas como la explicada por Nagao sobre la traducción humana: “la traducción de una frase no se consigue haciendo un análisis lingüístico profundo. En su lugar, normalmente lo que hacemos es descomponerla en elementos más pequeños y traducirlos al idioma objetivo. Por último, recomponemos estos fragmentos para formar la frase final”.
Estos sistemas conllevan tres procesos principales: emparejamiento, alineamiento y recombinación. Las técnicas de emparejamiento se pueden basar en caracteres, palabras y patrones. En el emparejamiento basado en caracteres se puede utilizar la distancia de edición y es sencillo de implementar, pero no tiene en cuenta la semántica, es decir, que no se extraen emparejamientos de sinónimos, por ejemplo.
La técnica basada en palabras muestra el uso de tesauros y diccionarios para encontrar palabras con significados similares; necesita un mayor procesamiento lingüístico y mayor base de conocimiento.
Por último, la técnica basada en patrones supone la generalización a través de clases equivalentes; se utilizan también patrones sintácticos y requiere el uso de analizadores sintácticos o parsers para ambos idiomas.
El doctor Duque Fernández habló igualmente de la traducción automática EBMT pura, o en tiempo de ejecución, que tiene su propio algoritmo, es un modelo sencillo, especialmente útil para palabras desconocidas o términos muy especializados; no resulta de tanta utilidad como modelo de traducción completo; se puede usar como complemento a otros modelos de traducción y es computacionalmente lento.
Los sistemas de la EBMT basada en ejemplos compilada comprenden aprendizaje de plantillas de traducción a partir de los ejemplos, se reduce el problema de dispersión de datos mediante la generalización y se aumenta la cobertura.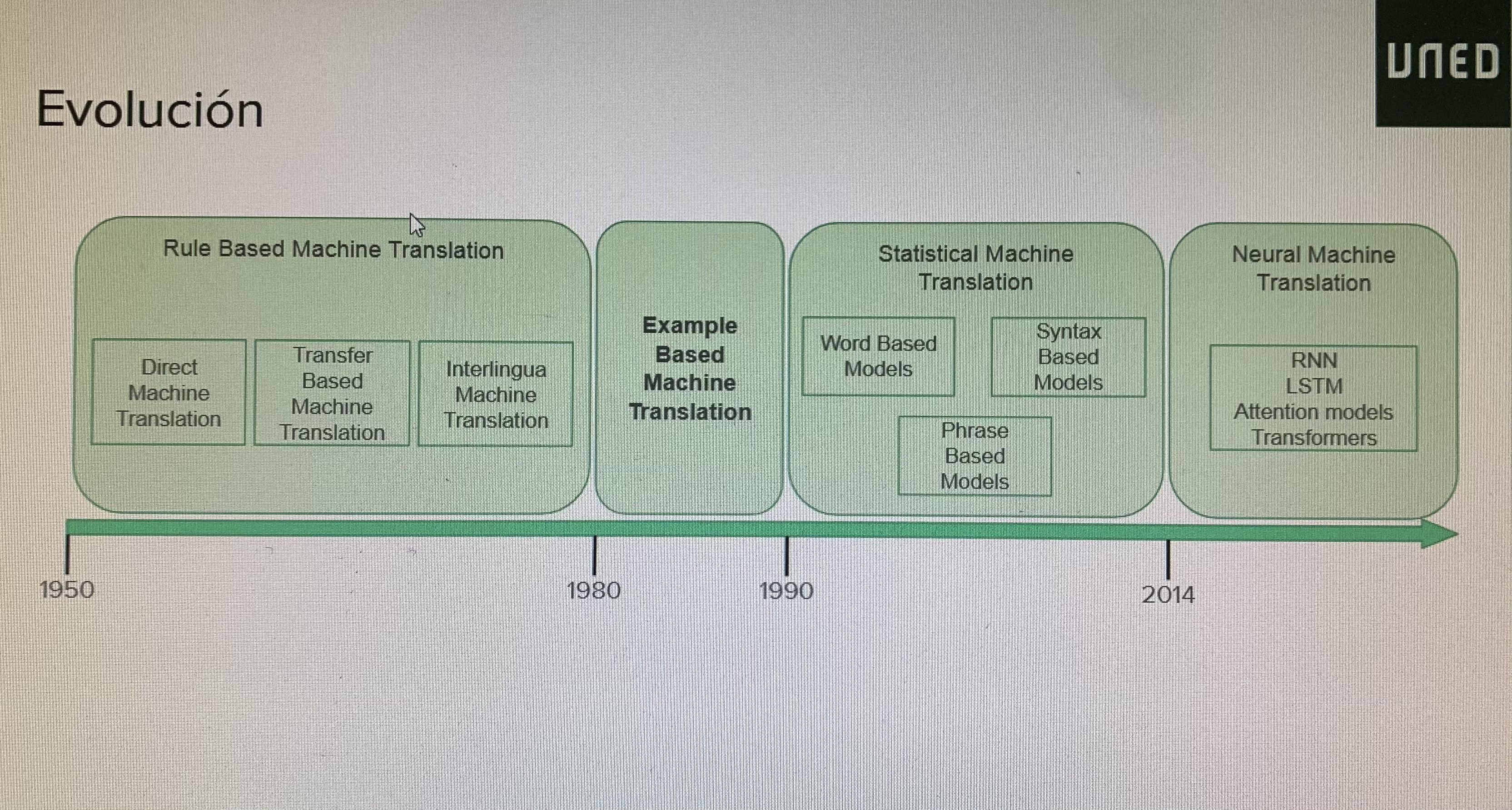
Según el ponente, los conflictos principales de la EBMT son: adecuación del corpus de ejemplos (ejemplos que se refuerzan unos a otros, ejemplos con conflictos y ejemplos contradictorios); selección del tipo de emparejamiento; en general EBMT funciona bien con datos específicos en dominios concretos, pero en general no se utiliza con fines comerciales. Este sistema rápidamente se vio eclipsado por la traducción automática estadística, aunque sigue presente en modelos híbridos.
Habló igualmente de los corpus paralelos como recurso fundamental para la traducción automática empírica, dirigida por datos. Son colecciones de textos en dos o más idiomas, presentan alineamiento a nivel de palabra, frase o sentencia, son diferentes a los corpus comparables, en los que los fragmentos de texto son similares y proceden del mismo dominio (género, temas tratados, etc). Sin embargo, dice Andrés Duque, estos corpus comparables no tienen por qué estar alineados. Los corpus comparables son pares de corpus monolingües que se han recolectado usando las mismas técnicas de muestreo.
De los corpus paralelos se espera limpieza, apropiación al dominio/género/estilo y un tamaño suficientemente grande. Estos corpus tienen generación manual (profesional o a través de crowdsourcing, según la estimación de compromiso coste/beneficio); y generación masiva, con procedimiento sencillo y capaz de recopilar grandes cantidades de datos; para generar corpus de forma masiva es necesaria la detección, tanto automática o no, de dominios web con datos paralelos. Los problemas que presenta esta generación masiva son datos ruidosos, datos ya generados por traducción automática y dominios particulares.
El ponente mencionó tres corpus:
- Europarl, con 21 idiomas, 1,4 millones de frases y 31 millones de palabras
- JRC-Acquis, con 22 idiomas; 2,9 millones de frases de media y una media de 48 millones de palabras
- OpenSubtitles, con 62 idiomas, una media de 54 millones de frases y 358 millones de palabras de media
Siguiendo con el avance temporal de la traducción automática, el profesor señaló cómo al iniciarse la década de los años 90 del siglo pasado surgió la traducción estadística (SMT) como modelo probabilístico a partir de los datos de corpus paralelos. Explicó su base teórica y su modelo de traducción así como su decodificación. Como señala Duque, se denomina decodificador al módulo de traducción automática que se encarga de realizar la traducción propiamente dicha, a partir del modelo aprendido. Y señaló diversos enfoques:
- Algoritmos voraces: es una traducción literal refinada iterativamente mediante heurísticas.
- Beam search: se trata de una decodificación de izquierda a derecha en la que el espacio de búsqueda es exponencial a la longitud de la frase y se produce la reducción de dicho espacio a partir del uso de heurísticas para reducir las hipótesis. Esta decodificación no garantiza una solución óptima, pero es una opción altamente eficiente.
La SMT basada en frases ofrece segmentación en frases, no se entiende frase como elemento lingüístico, sino como una secuencia de palabras consistente con el alineamiento a nivel de palabra. Una frase puede estar formada por un n-grama de palabras como elemento atómico. La segmentación en frases lleva a la traducción y a la reordenación. Hay diversas técnicas para la alineación a nivel de frase: generación a partir del alineamiento a nivel de palabra, plantillas de alineamiento y modelos conjuntos. La traducción automática estadística basada en frases (Phrase-based SMT) supuso el estado del arte en la industria hasta aproximadamente el año 2016.
Este sistema basado en frases tiene la ventaja de permitir la traducción muchos a muchos, usa el contexto local para la traducción y sus limitaciones son frases no continuas, algunas transformaciones sintácticas y el alineamiento, que sigue ofreciendo diversos problemas.
La traducción automática estadística (SMT) basada en sintaxis resulta más útil cuando se tratan idiomas con estructuras muy diferentes. Se incorpora información sintáctica al proceso de traducción utilizando árboles y formalismos gramaticales.
En general, los problemas que registra la SMT son el alineamiento a nivel de palabra, de frase; anomalías estadísticas como el traducir erróneamente nombres propios; aplicación de conjuntos de entrenamiento genéricos a dominios específicos; frases hechas, expresiones y otros problema se da en el orden de las palabras. Los desafíos pasan por crear corpus, conseguir gestionar los resultados inesperados y pares de idiomas con estructuras muy diferentes. Como señala el ponente, la SMT es un campo de investigación enorme cuyos mejores sistemas en general son complejos (cientos de detalles importantes, subcomponentes diseñados a mano; ingeniería de características para capturar fenómenos específicos de un idioma; recursos extra como tablas de equivalencia, etc. Y esfuerzo humano para cada par de idiomas.
Otro sistema son las redes neuronales y el aprendizaje profundo. La traducción automática neuronal (NMT) utiliza una única red neuronal, supuso una revolución en el año 2014 aproximadamente. Se ha establecido como estado del arte en la industria desde 2016 y presenta una arquitectura secuencia a secuencia. Duque señala que la NMT pasó de ser una actividad de investigación marginal al método estándar en dos años. En el 2014 se publicó el primer paper al respecto. En 2016 Google Translate pasó a utilizar la NMT. El SMT desarrollado por cientos de personas durante años fue desbancado por sistemas NMT entrenados por unas pocas personas en meses. Por último, en cuanto a ventajas, el NMT presenta mejores resultados, mejor uso del contexto; mejor similitud entre frases, mayor fluidez, sin subcomponentes y supone menor esfuerzo humano. Como inconvenientes presenta la interpretabilidad de los resultados, (con sistemas de caja negra, ciertas mejoras respecto a la atención y dificultades en la depuración) y es difícil de controlar, y por ello, hibridar.
En cuanto a si está resuelta la traducción automática, Andrés Duque presenta varios ejemplos para demostrar que no es así: problemas con las palabras polisémicas, expresiones propias de un idioma, sesgos variados, ya sean de género, de raza u otros. Los principales desafíos pasan por la gestión de las palabras fuera del vocabulario (copiado de palabras, traducción basada en caracteres y técnicas de subwording); corpus paralelos, sobre todo en idiomas con pocos recursos: para ellos, se trabaja en la transferencia de aprendizaje de modelos pre-entrenados y en medidas de ajuste, así como en la traducción automática no supervisada. Otro desafío es el mantenimiento del contexto en textos largos (con investigaciones sobre traducción guiada por el contexto, modelado separado del contexto para su utilización posterior y refuerzo del discurso). O el sesgo en datos de entrenamiento (para reducirlo se utilizan corpus con anotaciones concretas, por ejemplo de género; también se persigue la eliminación del sesgo anterior al entrenamiento hasta conseguir datos no sesgados, y o la eliminación del sesgo posterior al entrenamiento utilizando medidas de ajuste.
Este seminario de IA de la UNED en Ourense está patrocinado por el Vicerrectorado de Investigación, Transferencia del Conocimiento y Divulgación Científica de la UNED.
Ver la conferencia entera aquí.
 UNED Ourense
UNED Ourense
Comunicación

